What to know about Destinations
This page will help you understand how to work with our integrations system and get your first integration setup. Every destination has a unique set of connection requirements which will be covered in their specific docs. This document will cover the general process that you will need to follow for all destinations.
Open Your IntegrationsWhere to find the Destinations
- Access your dashboard https://app.heropixel.com
- In the left menu, on your dashboard, you'll see a link to Settings
- And then click the Integrations Tab (You can also click this link)
- Choose the "+ New Integration" button to get started
Choose your Destination
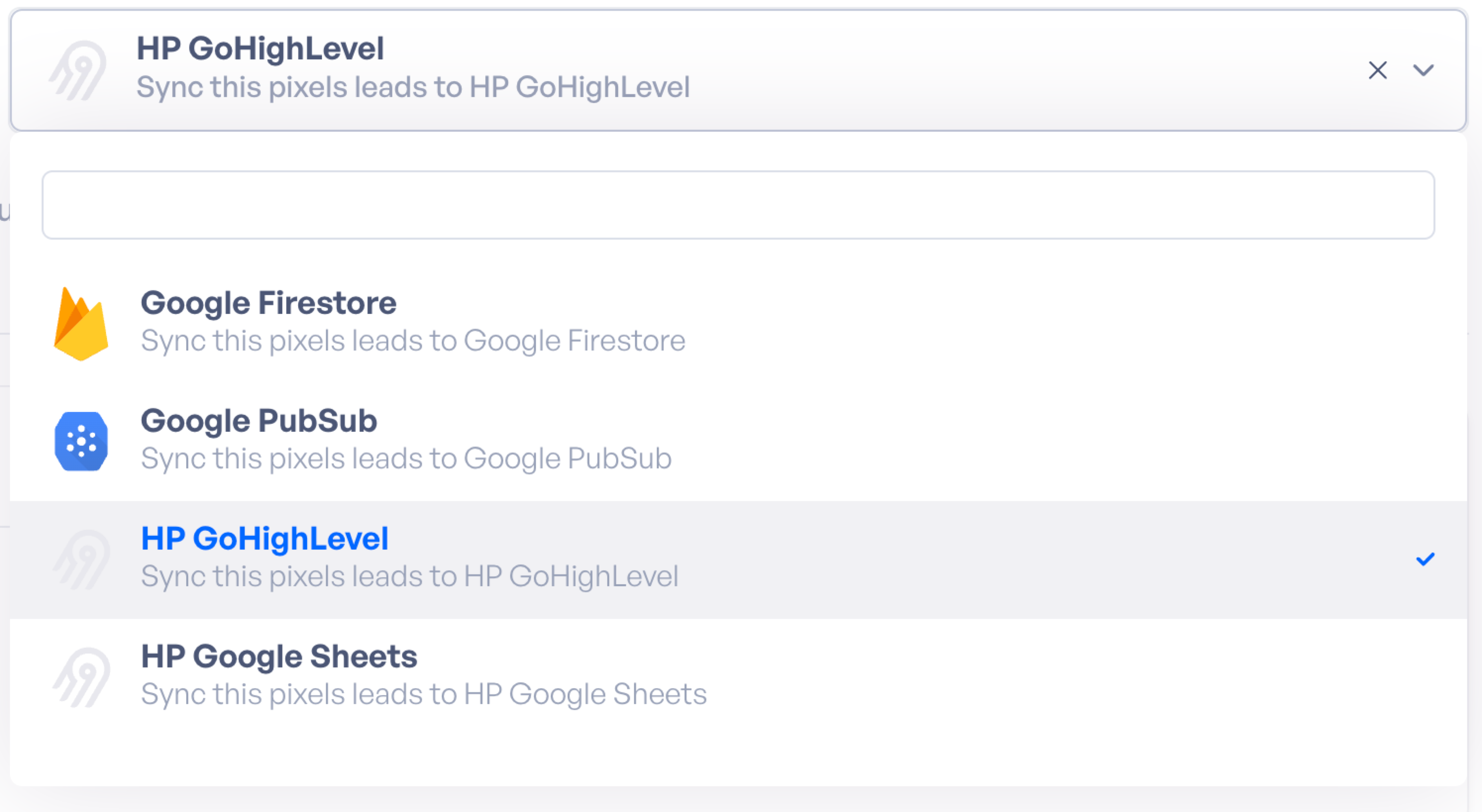
Once the integration configurations display we can begin by choosing our preferred destination. I've also provided you with a list of those destinations below, and a sidebar category called "Destinations" for your perusal.
You'll have your destination specific configurations that display, but under those there's two global settings, Stream Type and Sync Frequency.
Update Type
All integrations are set to only send you new data. It's called an Incremental Append. If you choose to have your integration a Full Refresh or other type of sync that's listed in the individual documentation, reach out to support and we can make that adjustment for you.
Stream Type
| Type | Description |
|---|---|
| Sync All Unique Individuals | Syncs all unique individual records from the chose pixel, ensuring that each person is represented once in the destination. This is ideal for a CRM. |
| Sync All Unique Sessions | Syncs all unique sessions, ensuring that each session (typically a user's interaction within a time frame) is captured once in the destination. This is ideal for remarketing ads or abandoned cart sessions. |
| Sync Every Pageview | Syncs every pageview event, capturing each time a page is viewed regardless of sessions or individual uniqueness. Ideal for segmenting your users based on the product pages they visit. |
Sync Frequency
You'll have the option to choose how often the sync runs and passes you data. Every hour, 2, 3, 4, 6, 8, 10, 12, or 24 hours.
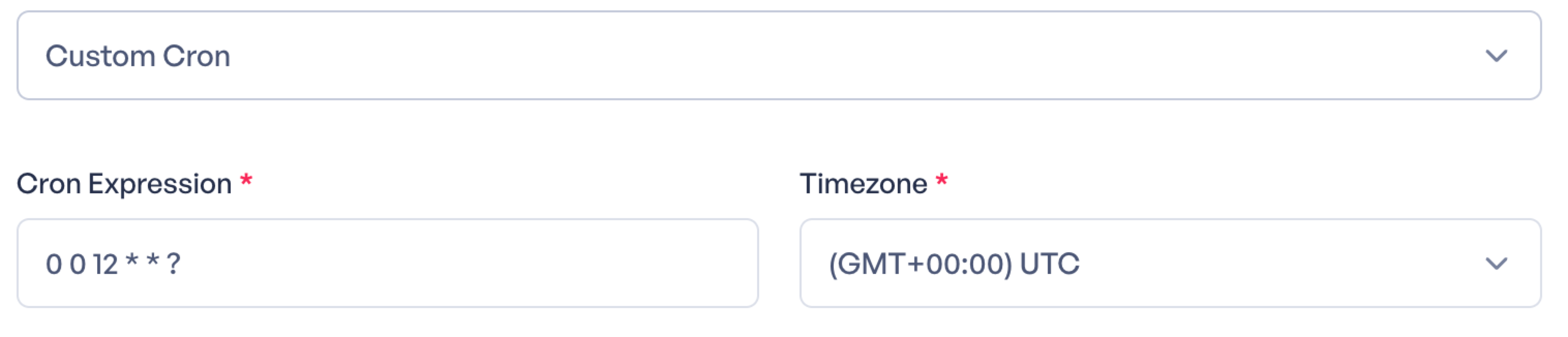 We also have a custom cron. If you'd like something other than the quick options provided, scroll to the bottom and choose custom schedule.
We also have a custom cron. If you'd like something other than the quick options provided, scroll to the bottom and choose custom schedule.
A cron is a time-based job scheduler in Unix-like operating systems. It allows users to schedule scripts or commands to run automatically at specified intervals, such as daily, weekly, or even down to the minute.
Use this tool to generate a cron schedule that fits your needs. Cron Schedule Tool
How Cron Works:
- Cron Jobs: A cron job is a specific task or command scheduled to run at a particular time.
- Cron Table (Crontab): This is a configuration file where cron jobs are defined. Each line in the crontab file represents a job, and includes the schedule, the command to be executed, and optional output redirection.
Cron Syntax: The schedule for a cron job is specified using five fields:
- Minute (0-59)
- Hour (0-23)
- Day of the month (1-31)
- Month (1-12)
- Day of the week (0-7), where both 0 and 7 represent Sunday.
For example, the following cron entry runs a script every day at 2:30 AM:
30 2 * * * /path/to/script.sh
Cron is powerful because it can automate repetitive tasks, ensuring they run consistently and on time without manual intervention.
Available Destinations
A destination is a location that we can send the data to. The following table lists various connectors with their logos, titles, descriptions, and links to their configuration docs.
| Logo | Title | Description | Link |
|---|---|---|---|
 | ASTRA | Astra is a cloud-native database-as-a-service built on Apache Cassandra. | Documentation |
 | AZURE BLOB STORAGE | Azure Blob Storage is a Microsoft cloud service for storing large amounts of unstructured data. | Documentation |
 | DATALAKE | AWS Data Lake is a centralized repository to store structured and unstructured data at any scale. | Documentation |
 | BIGQUERY | BigQuery is a fully-managed, serverless data warehouse that enables scalable analysis over petabytes of data. | Documentation |
 | CHROMA | Chroma is a vector database for building AI-powered applications with embeddings. | Documentation |
 | CLICKHOUSE | ClickHouse is a fast open-source columnar database management system for real-time analytics. | Documentation |
 | CONVERTKIT | Simple-to-Use and Efficient — Setting up automated email sequences is as easy as a few clicks saving you time and hassle. | Documentation |
 | CONVEX | Convex is a backend platform that provides real-time data synchronization and serverless functions. | Documentation |
 | DATABRICKS | Databricks is an Apache Spark-based analytics platform optimized for the cloud. | Documentation |
 | DUCKDB | DuckDB is an in-process SQL OLAP database management system. | Documentation |
 | DYNAMODB | Amazon DynamoDB is a key-value and document database that delivers single-digit millisecond performance. | Documentation |
 | ELASTICSEARCH | Elasticsearch is a distributed, RESTful search and analytics engine for all types of data. | Documentation |
 | FIREBOLT | Firebolt is a cloud data warehouse for delivering sub-second analytics at scale. | Documentation |
 | FIRESTORE | Firestore is a NoSQL document database built for automatic scaling, high performance, and ease of application development. | Documentation |
 | GCS | Google Cloud Storage (GCS) is a scalable, secure, and durable object storage service for developers and enterprises. | Documentation |
 | GOHIGHLEVEL | Go High Level Includes Landing Pages, Websites, Emails, Text Messaging, CRM, And Much More. | Documentation |
 | GOOGLE SHEETS | Google Sheets is an online spreadsheet app that lets users create and format spreadsheets and simultaneously work with other people. | Documentation |
 | HUBSPOT | Simplify Your Processes — Generate leads, close deals, and create remarkable customer experiences. | Documentation |
 | ICEBERG | Apache Iceberg is an open table format for huge analytic datasets. | Documentation |
 | KAFKA | Apache Kafka is a distributed event streaming platform capable of handling trillions of events a day. | Documentation |
 | KEAP | 53% More Leads with Keap — Organize, track, and nurture your leads and customers with Keaps powerful CRM tools. | Documentation |
 | KLAVIYO | Intelligent email marketing and SMS platform with automation for faster, more efficient growth. Turn your customer data into hyper-personalized messages. | Documentation |
 | MAILCHIMP | Use AI For Benchmarking, Creating Segments, Recommending Products & Generating Content. Convert Site Browsers, Cart Abandoners, & Cross-Sell Products to Discount Shoppers! | Documentation |
 | MILVUS | Milvus is a vector database for scalable similarity search in AI applications. | Documentation |
 | MONGODB | MongoDB is a source-available cross-platform document-oriented database program. | Documentation |
 | MSSQL | Microsoft SQL Server is a relational database management system developed by Microsoft. | Documentation |
 | MYSQL | MySQL is an open-source relational database management system based on SQL. | Documentation |
 | ONTRAPORT | Website, CRM & Marketing in 1 — Easy set up with award-winning support. Trusted by thousands of businesses. | Documentation |
 | ORACLE | Oracle Database is a multi-model database management system produced and marketed by Oracle Corporation. | Documentation |
 | PINECONE | Pinecone is a vector database that provides indexing and querying of large datasets of vector embeddings. | Documentation |
 | POSTGRES | PostgreSQL is a powerful, open-source object-relational database system. | Documentation |
 | PUBSUB | Google Cloud Pub/Sub is a messaging service for exchanging event data among applications and services. | Documentation |
 | QDRANT | Qdrant is a vector similarity search engine for finding similar entries in large-scale collections. | Documentation |
 | RABBITMQ | RabbitMQ is an open-source message broker software that implements the Advanced Message Queuing Protocol (AMQP). | Documentation |
 | REDIS | Redis is an open-source, in-memory data structure store, used as a database, cache, and message broker. | Documentation |
 | REDSHIFT | Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. | Documentation |
 | S3 | Amazon S3 (Simple Storage Service) is an object storage service offering scalability, data availability, security, and performance. | Documentation |
 | S3 GLUE | AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load data for analytics. | Documentation |
 | SFTP JSON | SFTP is a secure file transfer protocol used to transfer files over a secure channel. | Documentation |
 | SMARTLEAD | Fast, Easy and Reliable — Unlimited Warmups With Natural AI Conversations. Send cold emails that land in the inbox. Best Cold Email Tool in the Game. | Documentation |
 | SNOWFLAKE | Snowflake Cortex is a cloud data platform that provides data warehousing, data lakes, and data sharing capabilities. | Documentation |
| SNOWFLAKE | Snowflake is a cloud data platform that provides data warehousing, data lakes, and data sharing capabilities. | Documentation |
 | STARBURST GALAXY | Starburst Galaxy is a fully-managed cloud-native analytics platform based on Trino (formerly PrestoSQL). | Documentation |
 | TERADATA | Teradata is a cloud data analytics platform that helps manage and analyze large amounts of data. | Documentation |
 | TEXTHUB | Broadcast a mass text/sms message with the #1 rated platform. | Documentation |
 | TYPESENSE | Typesense is an open-source, typo-tolerant search engine optimized for developer happiness and performance. | Documentation |
 | VECTARA | Vectara is an AI-powered neural search engine that provides semantic search capabilities. | Documentation |
 | WEAVIATE | Weaviate is a vector search engine and database built to store, index, and search data objects. | Documentation |
 | WEBHOOK | A webhook is an HTTP-based callback function that allows lightweight, event-driven communication between 2 application programming. | Documentation |
 | YELLOWBRICK | Yellowbrick is a modern data warehouse for high-performance SQL analytics on-premises and in the cloud. | Documentation |